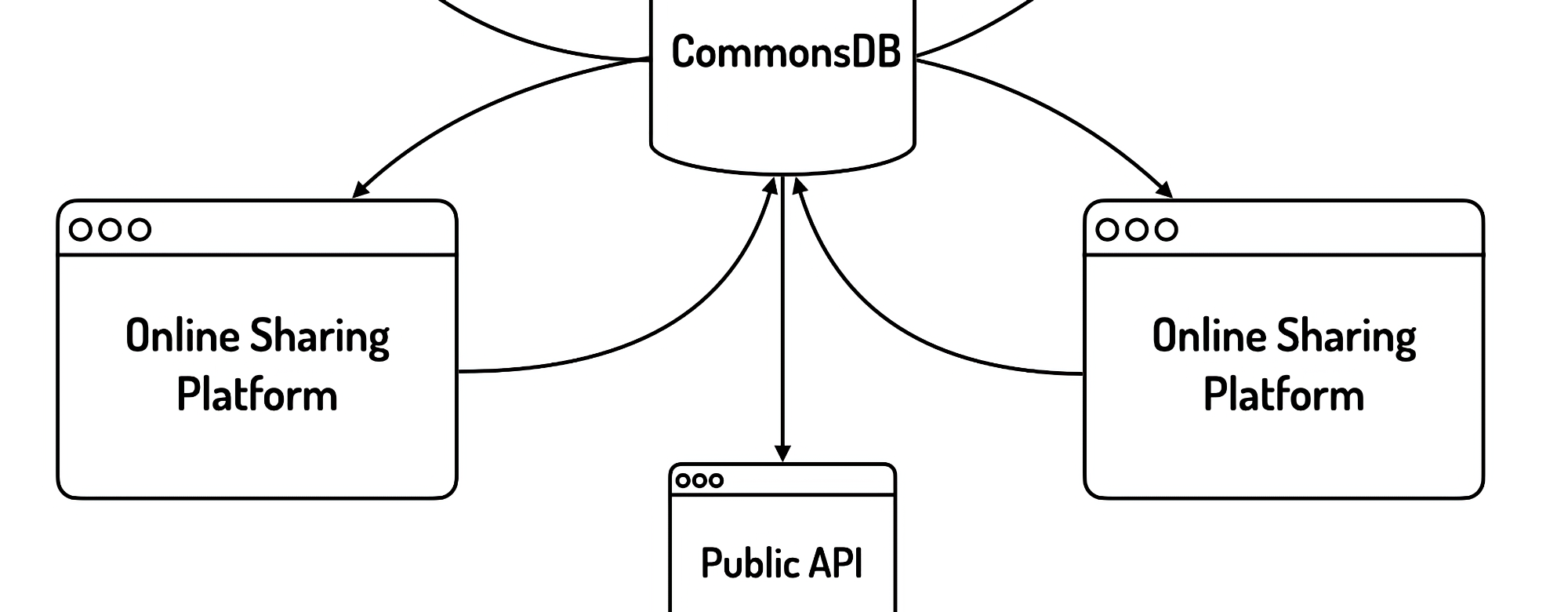
The Good, the Bad and the Missing – the new proposal for the implementation of the CDSM Directive into Polish law.
Poland has been waiting for the implementation of the CDSM Directive into national law for almost 5 years. During this time some early implementation projects appeared, and in 2022 public consultations were conducted, after which things went quiet. After winning the elections in October 2023, the new ruling coalition embarked on another attempt to regulate […]